GSoC, Symbolic planning techniques for recognizing objects domestic
#3
, Visual Inverse Kinematics
17 Jun 2015
Visual inverse kinematics, Basic understanding : In the previous post we anticipate the problems caused by the gaps and inaccuracies of motors in the inverse kinematics of the robot. Now, in this third post we will talk about the solution implemented during the GSoC15 project.
So, with the inverse kinematics component that we have implemented in Robocomp, we had the problem of inaccuracies and gaps in the robotic arm motors, problems that made the robot believed reach the target position without having actually achieved it. To solve this problem it was decided to implement a solution inside the visual field (which is what concerns us throughout this project), whose aim is to provide the inverse kinematics component a visual feedback that allows correct its mistakes. The operation of the algorithm is very simple and takes as its starting point the investigations of Seth Hutchinson, Greg Hager and Peter Corke, collected in A Tutorial on Visual Servo Control [1].
##’Looking’, then ‘moving’
As Hutchinson, Hager and Corke reflect in their work:
Vision is a useful robotic sensor since it mimics the human sense of vision and allows for non-contact measurement of the environment. […] Typically visual sensing and manipulation are combined in a open-loop fashion, ‘looking’ then ‘moving’.
So the goal of Visual servo control is to control the movement and location of the robot using visual techniques (detection and recognition of objects in an image). To get an idea how it works, we must have clear some fundamental concepts in this field
###Kinematics of a robot
We need to know what a kinematic chain is, what reference system and transformation coordinate are anda what algorithm is executed inside the robot kinematic. These concepts were explained in the second post of this collection. If you have doubts, consult it.
If we link the kinematic chains concept with visual techniques (ie, now, in addition to the chain formed by the motors of the robotic arm, we have a camera in the chain looking one of the chain ends), we have two types of systems:
- Endpoint open-loop (EOL): Systems which only observed the target object. These systems don’t need to look at his end effector so normally the camera is on the end effector (hand-eye).
- Endpoint closed-loop (ECL): Systems which observed the target object and the end effector of the arm.
The visual inverse kinematics that we implemented in Robocomp uses this last configuration because is independent of hand-eye calibration errors (precisely, the clearances errors and inaccuracies that bother us in the inverse kinematics), although often requires solution of a more demanding vision problem, because we need to track the end effector.
###Camera Projection Models
We need to understand the geometric aspects of the imaging process if we want to understand how the information provided by the vision system is used to control the movement of the robot. The first thing to consider is that an image taken by a camera is always in 2D, so we’re losing spatial information (the depth of the scene).

To resolve this issue we have several options:
- We can use multiple cameras that capture the studio space from different positions.
- We can obtain multiple views with a single camera.
- We can have previously stored the geometric relationship between certain characteristics of the target or the elements in the studio space.
In any case, we must keep in mind certain things common to all cameras. For example the system of axes: the X and Y axes form the basis of the image plane and the Z axis is perpendicular to the image plane, along the optical axis of the camera. The origin is located on the Z axis at a distance λ of the image plane. That distance λ is what we call focal length.
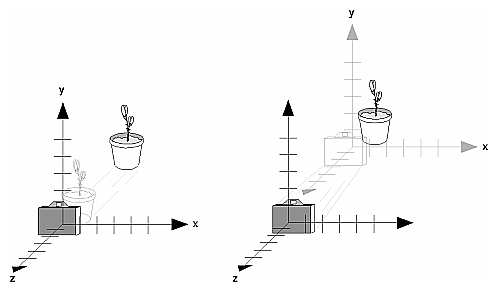
We can map the position and the orientation of the end effector in space calculating the projective geometry of the camera. But this method, complicated in itself, increases their difficulty because we need recognize the end effector in the picture, in addition to deriving the speed from the changes observed in each frame that the camera capture. For these reasons, in our visual inverse kinematic component, we use the algorithm proposed by Edwin Olson, Apriltags [2] a visual fiducial system that uses a 2D barcode style tag (binary, black and white synthetic brands), allowing full 6 DOF localization of features from a single image. Thus, if we put a apriltag in the end effector, we can get its position and orientation in a very simple way.
##visualBIK component
Having already some clear concepts, let us study how the component developed in this project, visualBIK, works.
Our component implements a simple state machine where waits the reception of a target position (a vector with traslations and rotations: [tx, ty, tz, rx, ry, rz]) through its interface. When a target is received, the visualBIK send it to the inverse kinematics component like a POSE6D target, and waits for him to finish running the target and placing the arm. As the end effector will be a little out of the target position (due to inaccuracies), the visualBIK will be prepared to correct this error:
- It calculates the visual pose of the end effector (through apriltags, visualBIK receives the position of the end effector mark that the camera head sees).
- After, it compute the error vector between the visual pose and the target pose.
- With this error vector, visualBIK corrects the target pose and sends the new position to the inverse kinematics component.
- This process is repeated until the error achieved in translation and rotation is less than a predetermined threshold.
In this way we can correct the errors introduced by the inaccuracies of the joints.
This component (like component inverse kinematics) is still in the testing phase and is more than likely suffer some changes that improve its operation.
Bye!
[1] Hutchinson, S., Hager, G., Corke, P. A Tutorial on Visual Servo Control, IEEE Trans. Robot. Automat., 12(5):651–670, Oct. 1996. Download in http://www-cvr.ai.uiuc.edu/~seth/ResPages/pdfs/HutHagCor96.pdf
[2] OLson, E. AprilTag: A robust and flexible visual fiducial system, Robotics and Automation (ICRA), 2011 IEEE International Conference on, 3400-3407