DuelingDQN Agent
Dueling DQN Agent
In DuelingDQN, we split calculate the State-Action-Values (Q) using State-Values (V) and Advantage function (A) By decoupling the estimation, intuitively the DuelingDQN agent can learn which states are (or are not) valuable without having to learn the effect of each action at each state (since its also calculating V).


Environment Setup
We are generating the scene such that the humans are placed on a radius of r meters and the robot and goal is placed within this circle. The objective of the robot is to reach the goal by avoiding collisions with the humans.
The humans also move during an episode towards the diametrically opposite direction and thus it becomes difficult for the robot to navigate to get to the goal position. The number of humans in every episode keeps changing. However, in no episode will there be no less than 2 humans and more than 8 humans. The humans move with variable velocity at every timestep of the episode. This makes it difficult to predict their next position. Also, the humans are not programmed to avoid the robot at all. Hence, on collision we stop the episode so that the collision does not destabilise the robot. Based on this experimental setup and using no fancy tricks, a purely DuelingDQN agent learns pretty decently.
https://user-images.githubusercontent.com/39992294/128507394-a955704d-4090-4085-aa1d-7b56bdfa9b83.mp4
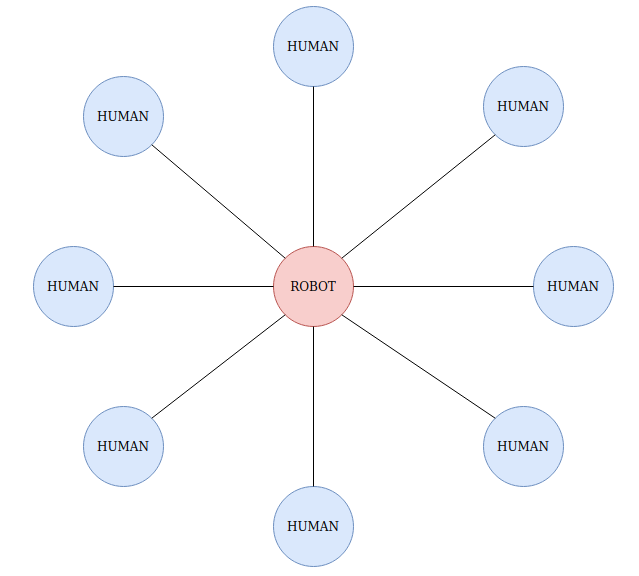
Neural Network Architecture
The Neural Network is a Graph Attention Network and the graph used is a star graph. The robot shares an edge with every human in the room. Every entity in the room, that is, humans and robot can be considered nodes of a graph and every node is associated with a feature vector. The attention module of the GAT computes attention weights based on the similarity score between two feature vectors (in this case, it would be the feature vector of the robot and the feature vector of every other human in the room). After computing the attention weights, it multiplies them with the feature vector of the respective humans which is then aggregated. This aggregated feature vector is then concatenated with the feature vector of the robot and that is used to compute the State-Action-Values, that is the Q function.
Results
Reward Curve
The reward structure is such that, the robot get penalised with the L2 distance betweeen its current position and the goal position and if it collides with a human. It gets a positive reward if it reaches the goal position.

Performance
This is how the robot behaves when we train it for roughly 30K episodes.
https://user-images.githubusercontent.com/39992294/128508414-2b463598-4c36-4dcd-a225-40c737429a26.mp4